기본적인 Apod 기능을 구현하기 위해 웹 크롤링 부분을 구현하였습니다.
1. 구현된 기능
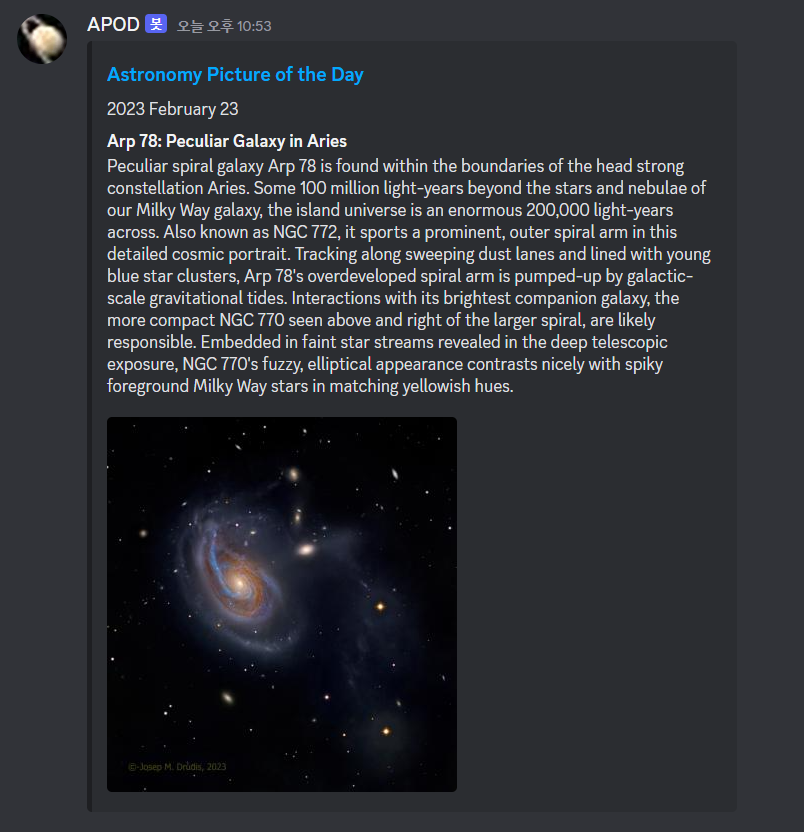
~apod 명령어를 입력하면 그날의 apod 정보를 크롤링하여 메시지를 보낸다. 가시성을 위해 Discord의 포함 형식을 사용했습니다.
2. 구현 코드 및 설명
크롤링 방법 자체는 여러 사이트에 나와 있지만 BeautifulSoup4를 사용했습니다. 아래 공식 문서를 주로 참고했고 필요할 때마다 구글링을 했다.
뷰티풀수프 문서 — 뷰티플수프 4.0.0 문서
find_all() 메서드는 태그의 자손을 찾고 지정된 필터와 일치하는 경우 모두 추출합니다. 몇 가지 필터에서 예를 들었지만 여기서는 몇 가지 더 보여드리겠습니다. 익숙한 것, 다른 것
www.crummy.com
전체 코드는 다음과 같습니다. 기능 구현에만 집중하다 보니 여전히 번거롭습니다.
import discord
import requests
from bs4 import BeautifulSoup
bot_token = '봇 토큰'
intents = discord.Intents.default()
intents.message_content = True
client = discord.Client(intents=intents)
url = "https://apod.nasa.gov/"
response = requests.get(url)
@client.event
async def on_ready():
print(f'Logged in as {client.user.name}')
@client.event
async def on_message(message):
if message.author == client.user:
return
#~apod
if message.content('~apod'):
#~apod today
response.encoding = 'utf-8' #인코딩 설정
response_html = response.text #html 파일 추출
response_soup = BeautifulSoup(response_html, features="lxml") #soup 객체로 변환
apod_date = response_soup.body.center.p.next_sibling.get_text().replace("\n", "")
apod_title = response_soup.select_one('center > b').get_text()
apod_explanation = response_soup.select_one('body > p').get_text().replace("\n", " ")(14:)
apod_image = response_soup.select_one('body center p a img')('src')
apod_embed = discord.Embed(title="Astronomy Picture of the Day", url="https://apod.nasa.gov/", description=f"{apod_date}")
apod_embed.set_image(url="https://apod.nasa.gov/apod/" + apod_image)
apod_embed.add_field(name=apod_title, value=apod_explanation)
await message.channel.send(embed = apod_embed)
#~apod YY-MM-DD
if message.content("~apod 00-00-00"):
print()
#~apod alarm
if message.content("~apod alarm"):
print()
#~apod help
if message.content("~apod help"):
print()
client.run(bot_token)
기본 크롤링 프로세스는 다음과 같습니다.
0. robots.txt 파일 확인
크롤링하기 전에 사이트에서 크롤링을 금지하는지 확인하십시오. 필수는 아니지만 사이트에서 권장하는 내용을 확인하기 위해 가능하면 크롤링하기 전에 살펴보는 경향이 있습니다.
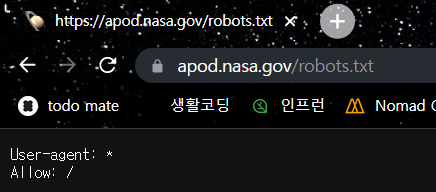
Apod 사이트는 모든 페이지에 대한 액세스를 허용합니다.
1. 요청 모듈을 사용하여 GET 요청 보내기
url = "https://apod.nasa.gov/"
response = requests.get(url)요청 모듈을 사용하여 웹 사이트에 GET 요청을 보냅니다. 응답에는 상태 코드(200, 404…) 및 HTML이 포함됩니다.
2. GET의 결과인 응답에서 HTML을 가져오고 BeautifulSoup 개체를 만듭니다.
response.encoding = 'utf-8' #인코딩 설정
response_html = response.text #html 파일 추출
response_soup = BeautifulSoup(response_html, features="lxml") #soup 객체로 변환3. BeautifulSoup 개체에서 필요한 정보가 있는 태그를 찾아 각 변수에 할당합니다.
apod_date = response_soup.body.center.p.next_sibling.get_text().replace("\n", "")
apod_title = response_soup.select_one('center > b').get_text()
apod_explanation = response_soup.select_one('body > p').get_text().replace("\n", " ")(14:)
apod_image = response_soup.select_one('body center p a img')('src')
각 방법에 대한 자세한 내용은 공식 문서를 참조하세요.
뷰티풀수프 문서 — 뷰티플수프 4.0.0 문서
find_all() 메서드는 태그의 자손을 찾고 지정된 필터와 일치하는 경우 모두 추출합니다. 몇 가지 필터에서 예를 들었지만 여기서는 몇 가지 더 보여드리겠습니다. 익숙한 것, 다른 것
www.crummy.com
4. Discord 임베딩을 생성한 후 필요에 따라 변수를 추가하고 메시지를 보냅니다.
apod_embed = discord.Embed(title="Astronomy Picture of the Day", url="https://apod.nasa.gov/", description=f"{apod_date}")
apod_embed.set_image(url="https://apod.nasa.gov/apod/" + apod_image)
apod_embed.add_field(name=apod_title, value=apod_explanation)
await message.channel.send(embed = apod_embed)
3. 참조 페이지
https://velog.io/@chaejm55/%EB%B2%88%EC%99%B82.-embed-%EC%9D%B4%EB%AF%B8%EC%A7%80